Pattern · Cross-sector · April 2026
Replacing legacy field-service applications without disrupting operations
How we migrate operationally critical field-service applications onto the operator's existing enterprise platform — preserving the workflow, replacing the lock-in. Worked example: a continental field-service replacement that ran every shift through the cutover without missing a dispatch.
The situation
A North American operator was running a vendor field-service application on top of its existing enterprise platform to schedule, dispatch, and route hundreds of technicians across a continental footprint. As the technician headcount grew, the per-resource licensing model began to dominate platform spend. Worse, the dispatch logic the operations team actually wanted — region-specific routing rules, custom skill matching, multi-stop optimization for remote service areas — was either unavailable in the vendor module or required workarounds that were brittle and hard to maintain.
Three options were on the table: stay on the vendor module and accept the cost, migrate to a competing third-party field-service platform (creating yet another integration surface), or build a bespoke equivalent directly on the platform the operator already ran. The operator chose the third path on the condition that the replacement could not interrupt a single shift’s operations during cutover. This pattern generalises: most operators with a paid-per-resource module on top of an enterprise platform eventually face the same choice.
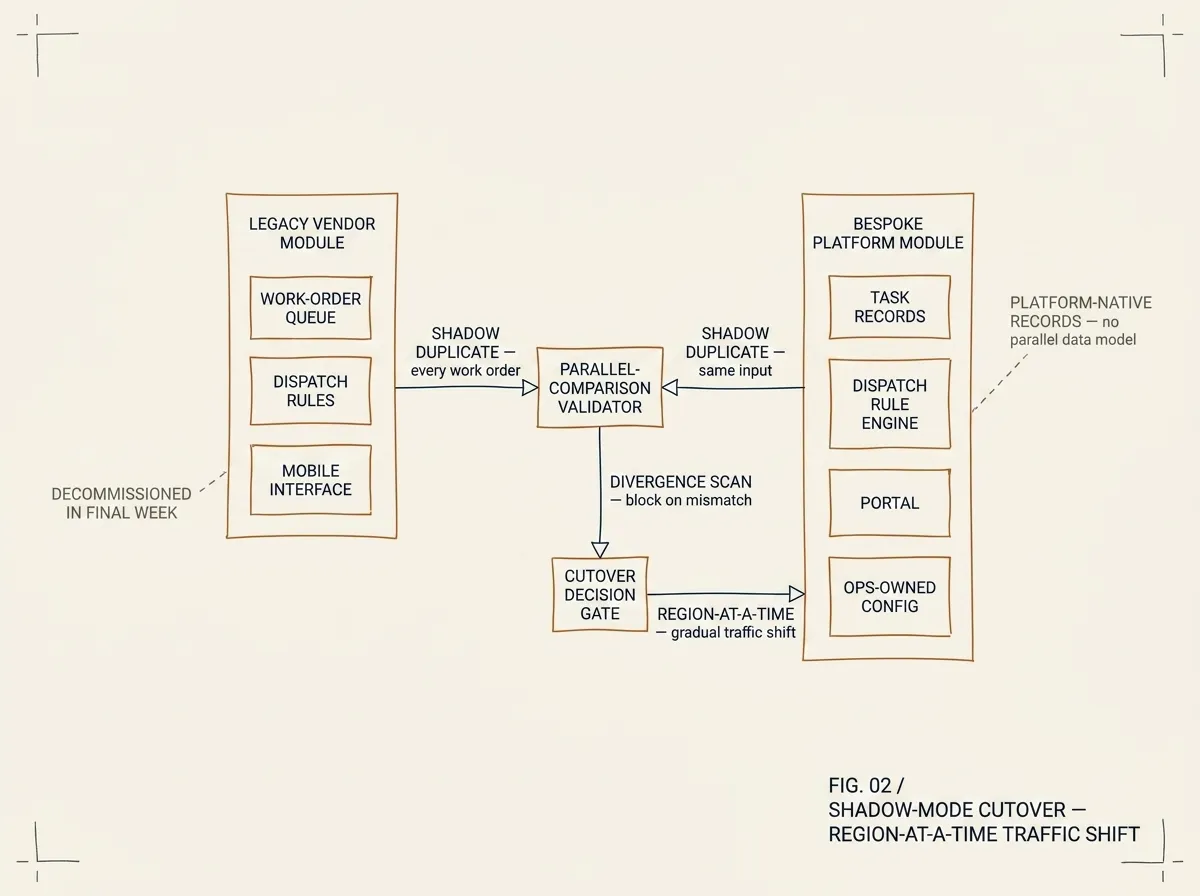
FIG. 02 / SHADOW-MODE CUTOVER — every work order is duplicated into both modules and reconciled by the parallel-comparison validator. Traffic shifts region-by-region only after divergence drops to zero. The legacy module is decommissioned in the final week.
What we built
We built a native field-service application on the operator’s existing enterprise platform that replicates the vendor module’s core capabilities — work-order scheduling, technician dispatch, route optimization, mobile field interface, completion workflows — using the platform’s native task and asset records, its scripted resource layer, and its portal framework. Critically, the application reuses the operator’s existing customer-service and asset records; field operations and the rest of the business now sit in the same data model rather than synchronised across two.
The architecture avoided the most common custom-application failure mode: building a parallel data model that drifts from platform conventions. We used the platform’s standard task and asset record extensions throughout, which means the application benefits from every platform upgrade rather than fighting against them.
For dispatch logic, we implemented a rule engine on top of the platform’s flow framework that lets the operations team configure their own routing rules without writing code. The engine handles the operator’s actual constraints — territory boundaries, technician certifications, drive-time zones in remote service areas, multi-stop optimization where the next site is closer than the home depot — none of which the vendor module handled cleanly.
The same architectural shape applies to other legacy-to-platform migrations: identify the applications whose data already wants to live in the platform’s data model, build natively against the standard record extensions, expose configuration to the operations team rather than gatekeeping it behind a vendor escalation path.
How we cut over without disruption
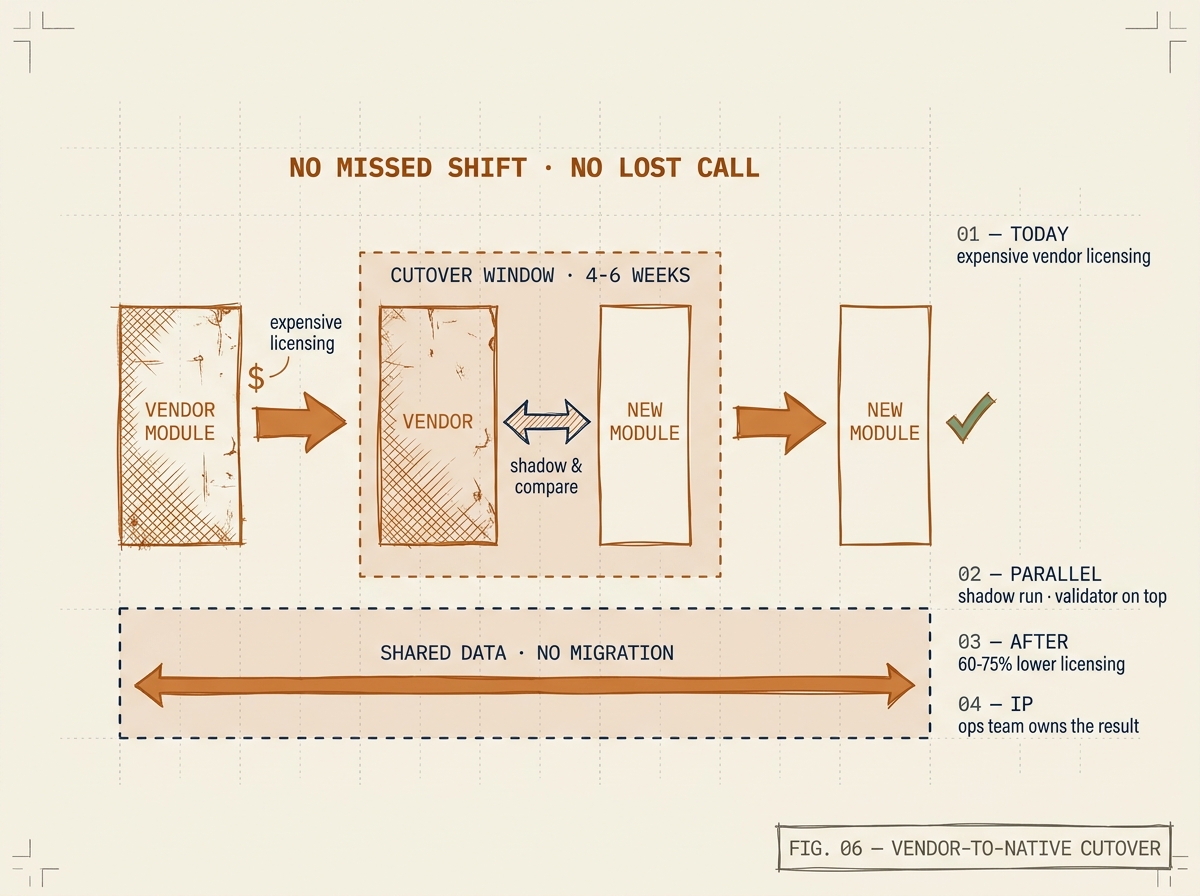
Cutover happened in three phases over six weeks. Phase one ran the new module in shadow mode: every vendor work order was duplicated into the new system, dispatched in parallel, and the outputs compared. Phase two moved a single region’s dispatchers to the new system while the rest stayed on the vendor module; the parallel comparison continued for that region. Phase three migrated remaining regions in weekly waves. The vendor module was decommissioned in the final week of the engagement.
No shift missed a dispatch. No technician saw an interface change without a week of overlap and training. The operations team had a rollback path until the final week.
What this pattern is good for
This pattern works when three things are true: the customer already runs an enterprise platform that holds the relevant records (or is willing to make it one for the application in scope), the cost of the legacy application — measured in licensing, vendor escalation overhead, or evolution velocity — is large enough to justify a build, and the customer wants long-term control over the application’s behaviour. If any of those is missing, sticking with the vendor module or moving to a competitor is usually the right call.
If they’re all true, the bespoke build pays back the engagement cost typically within the first year of avoided licensing alone — and the customer owns the result forever. The pattern is not field-service-specific; we have used the same approach for case management, internal IT applications, and asset management modules where the vendor module’s pricing or rigidity had become operationally limiting.
Recognise this pattern?
Tell us about yours.
If your problem rhymes with this one, scoping a project usually takes us less than a week. References available under NDA.
Talk to an engineer →